Un sistema de control de versiones (SCV) es un software que nos permite llevar un historial de las distintas versiones por las que va atravesando el desarrollo de un producto, normalmente software. Existen multitud de herramientas ahí afuera, aunque si hay que elegir alguna, Subversion es con diferencia la más usada. Por ahora.
Subversion es un SCV centralizado. Esto quiere decir que requiere de un servidor donde alojar el repositorio del proyecto, y al que los distintos desarrolladores acceden para recuperar o actualizar los cambios del producto en desarrollo.
El esquema de un SCV centralizado sería el siguiente:
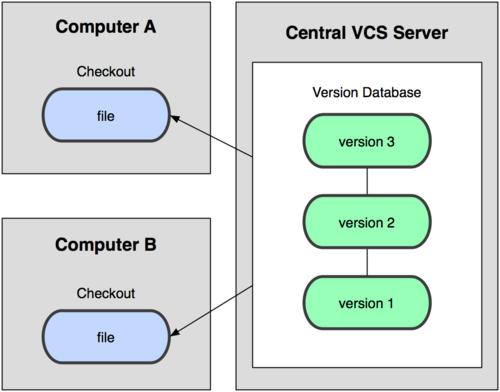
(Vía http://progit.org/book/)
El principal inconveniente de este esquema es que dependemos al 100% de la integridad del servidor. Un corte de conexión atrasaría el desarrollo del producto durante un tiempo. La pérdida de datos supondría la pérdida de todo el historial de desarrollo (algo que se podría evitar con copias de seguridad, claro).
Git es otro SCV, aunque a diferencia de Subversion, Git es un sistema de control de versiones distribuido. En un SCV distribuido el historial del proyecto no se aloja sólo en el servidor. En lugar de esto, cada desarrollador tiene su propia copia del historial. Además la existencia de un servidor donde alojar el historial se convierte en algo opcional.
El esquema de un SCV distribuido sería el siguiente:
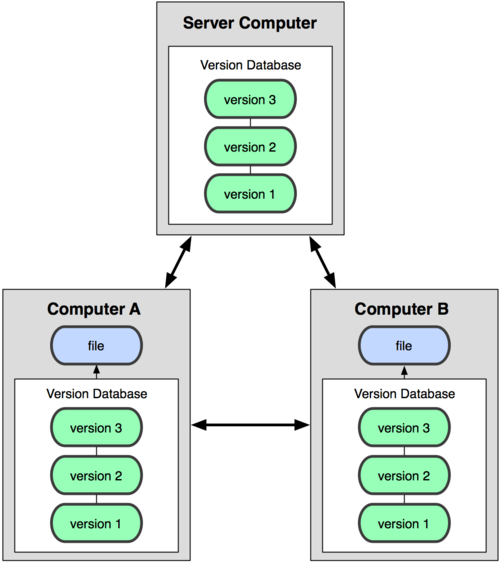
(Vía http://progit.org/book/)
Como se ve en el diagrama, el flujo de trabajo es diferente del que había con un sistema centralizado. Ahora cada desarrollador dispone de una copia completa del repositorio, pudiendo además recuperar/actualizar los cambios entre dos o más repositorios. Además cada desarrollador envía los commits a su propio repositorio local, con lo que puede trabajar sin necesidad de estar conectado.
Git nació en 2005 como un proyecto liderado por Linus Torvalds, creador de Linux. Entre sus objetivos estaba el crear un SCV rápido y seguro que permitiera un desarrollo distribuido del kernel de Linux. Hoy en día son muchos los que colaboran en el desarrollo de esta gran herramienta, haciendo que Git se haya convertido en los últimos años en uno de los SCV más usados, gracias en otras cosas a GitHub.
Entre las principales ventajas de Git están la rapidez, la eficiencia, la seguridad y sobre todo la flexibilidad. Aunque quizá ésta última pueda convertirse al principio en un inconveniente.
Y bueno, después de toda esta introducción y cúmulo de piropos, vamos al grano: voy a mostrar algunos de los principales comandos que puedes usar en Git.
Comenzando con Git
Recordemos que en Git se trabaja con un repositorio local. Para crearlo sólo tendremos que situarnos en el directorio del proyecto y poner:
git init
Con eso ya tendremos el repositorio creado y nuestro proyecto bajo revisión. A diferencia de Subversion, Git sólo crea un directorio oculto (.git/) en la raíz del directorio. A partir de aquí ya podremos enviar commits y movernos a través del historial.
Lo primero que tendremos que hacer será añadir todos los archivos de nuestro proyecto al repositorio recién creado, ya que éste inicialmente estará vacío. Para añadir todos los archivos del proyecto escribimos:
git add *
Git añade los archivos al index. El index es algo así como una agenda donde se van apuntando los archivos que se añaden y se borran en el repositorio.
Para ver el estado actual del repositorio escribimos:
git status
Y para guardar definitivamente los cambios en nuestro repositorio escribimos:
git commit -am "Commit inicial"
Podemos ver el historial de commits que hemos hecho con:
git log
Aunque existe una herramienta visual que nos permite ver el historial de una forma mucho más cómoda: gitk, disponible en los repositorios de cualquier distribución Linux.
A continuación voy a hablar un poco de las ramas (branches). En Git podemos trabajar con múltiples versiones de nuestro proyecto, lo que nos permite separar la versión principal de desarrollo de otras versiones: pruebas, correcciones, versiones estables, etc. A diferencia de Subversion, Git está diseñado para trabajar con múltiples ramas de una forma natural y sencilla, ofreciendo una amplia gama de comandos para manipularlas.
Por defecto la rama principal es la master. Para crear una nueva rama, a la que llamaremos “foobar”, sólo hay que hacer:
git branch foobar
Si a continuación escribimos:
git branch
Git nos indicará que estamos actualmente en la rama foobar. A partir de ahora todos los cambios y commits que hagamos se irán almacenando en esta rama del proyecto, sin afectar a la rama principal (master), teniendo por tanto dos líneas de desarrollo diferentes e independientes. Aunque podríamos tener muchas más.
Una vez que decidamos incluir en la versión estable todos los cambios introducidos en la versión foobar, sólo habrá que hacer una fusión de ambas ramas. Para ello usaremos el comando merge.
Para hacer un merge de la rama foobar con la master, primero nos cambiamos a la rama master:
git checkout master
y a continuación la fusionamos con la rama foobar:
git merge foobar
A partir de este momento ambas ramas vuelven a ser exactamente iguales. Si queremos cambiarnos de nuevo a la versión foobar escribimos:
git checkout foobar
Y si por contra preferimos eliminarla:
git branch -d foobar
Y por último, para no extenderme demasiado con este artículo, ahí va un magnífico libro para aprender a manejar este potente sistema de control de versiones:
Pro Git - Scott Chacon, Ben Strau
¡Ah! Y por si os resulta útil, aquí tenéis una chuleta con los principales comandos que he ido usando a lo largo del tiempo.